
もう今は見ることができない古いWebページを見たいと思ったら、Internet Archive(インターネット・アーカイブ)という海外のサービスで探してみてください。このInternet Archiveとは、一言で言うと全世界のWebページをスナップショットで保存しているサービスです。
「使う機会(必要)がない」と言われてしまうと終わりですが、実はビジネスでもプライベートでも色々と活用方法が考えられる代物です。例えば、私は仕事で公的な機関への説明資料にも使用したことがあります。個人顧客との間で裁判外紛争(ADR)の調停があり、10年ほど前にWebページで何を表示していたかの客観的な説明資料として提出して認められています。

そんなユニークなInternet Archiveについて、一体どのようなサービスなのか、どのような使い方ができるのか、実際にいくつかの懐かしいWebサイトを例にしながらご紹介してみたいと思います。
Internet Archive(Wayback Machine)とは
まず最初に、Internet ArchiveのことをWkipediaの記事を引用する形で確認しておきましょう。
インターネットアーカイブ(The Internet Archive) は、WWW・マルチメディア資料のアーカイブ閲覧サービスとして有名なウェイバックマシン(Wayback Machine)を運営している団体である。本部はカリフォルニア州サンフランシスコのリッチモンド地区に置かれている。
アーカイブにはプログラムが自動で、または利用者が手動で収集したウェブページのコピー(ウェブアーカイブ)が混在しており、これは「WWWのスナップショット」と呼ばれる。そのほか、ソフトウェア・映画・本・録音データ(音楽バンドなどの許可によるライブ公演の録音も含む)などがある。アーカイブは、それらの資料を無償で提供している。
アーカイブされている古いデータを見れば分かりますが、インターネット回線がADSLより前のISDNくらい細い回線の時代までさかのぼれます。設立された1996年から全世界のWebページがアーカイブされていて、対象が大手サイトであるほどクロールされた当時のページを多く見ることができます。
Internet Archiveはアメリカ人のブリュースター・ケール(Brewster Kahle)が設立し、この起業家は「インターネット視聴率」とも言われるAlexa Internet(アレクサ・インターネット)を作った人物でもあります。ちなみに、Alexa.comはamazonが1999年に買収しています。今でもAlexa.comはWayback Machine(Internet Archive)に情報を送っていると書かれていますね。
ブリュースター・ケースは「全知識体系への全世界的アクセス(Universal Access to all Knowledge)」を目標に掲げているそうで、これは「世界中の情報を体系化し、アクセス可能で有益なものにする」というGoogleの使命にも似ていると感じました。

2024年1月現在、Internet Archiveには8630億ページ(863billion web pages)がアーカイブされていて、日本語のサイトも広範にアーカイブされていることが確認できます。この記事を最初に書いたのは2018年1月でしたが、そのときと比べるとアーカイブされているページは直近6年間で倍増しているようです。
Weyack Machineの使い方や注意点
それでは実際にInternet ArchiveのWeyback Machineを使う方法や注意点を説明していきます。
見たいWebサイトの検索
まずはInternet Archiveに保存されているWebページ探す方法ですが、これは検索エンジンを探す感覚と同じなので迷うポイントはないでしょう。TOPページにある検索ボックスに、振り返りたいWebサイトのURLもしくは検索キーワードを入力します。今は存在しないURLでも大丈夫です。
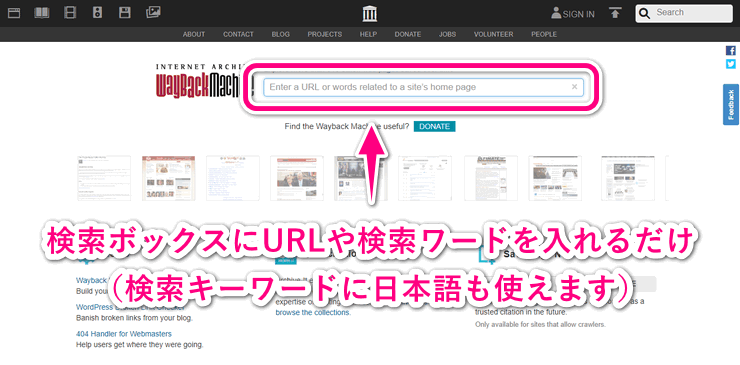
あとは、検索結果で出てきた中に探しているサイトがあれば選択してください。選択すると下の画像のようにアーカイブされた年と日付が出てくるので、そのサイトがアーカイブされた日付を選択してください。
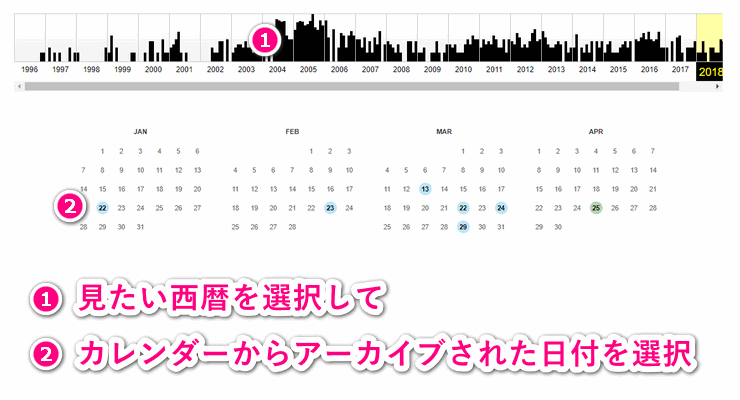
上の画像は日本の財務省(mofa.go.jp)のWebサイトを検索した結果です。1996年の大蔵省時代からアーカイブされていて、2003年~2005年にかけてが一番アーカイブされていますが、棒グラフを見ると月によっては全くアーカイブされていない月もあるようです。
大手のサイトによっては高頻度でクロールされてアーカイブされていますが、サイトによっては月1回程度しかアーカイブされていなかったり、サイトやページによってはアーカイブ自体がないこともあります。
このように検索エンジンでWebページを探すような感覚で、Internet Archiveがクロールした時点のWebページを簡単に確認することができます。表示されたページのリンクもクリックできるので、そのまま過去のページを巡ることも可能です。
Webページの保存は完全ではありません
いくつかのページを見ていけば分かると思いますが、Webページのアーカイブは完全なものではありません。古いサイトほどページ内の動的な部分の再現はマチマチです。
簡易なFlashやJavaScript程度は丸ごとスクリプト自体が保存されて動くようですが、ページ内検索などでDB(データベース)にアクセスするものは基本的に動きません。また、画像についてもオンマウスしたものは表示されないなど、ページ内で画像やCSS(デザイン)が欠落しているものもあります。これは技術的な問題でしょう。
もう一つ技術的な話として、metaタグでnoindex(検索エンジンに登録しない)を宣言しているページはアーカイブされないので、Googleなどの検索エンジンにもインデックスされないようにしているWebサイトは見つかりません。
反対に、ほとんどのサイトはアーカイブされることを意識されていないと思いますが、noindexにしておけばWayback Machineにも登録されないということになります。もちろん、Googleなどの検索エンジンにもインデックスされなくなるので、noindex自体はInternet Archiveを回避するために使うものではありませんね。
Internet Archiveにある保存されたページのサンプル
ここからは、実際にInternet Archiveに保存されているWebページのサンプルをご紹介していきましょう。
家庭では光回線の普及、携帯電話では4Gが出てきたころから、Webサイトのリッチ化(高画質な画像や動画などの増加)が急速に進みました。そんな最近の話では面白くないので、ここではダイヤルアップ回線やADSLなどが主流だった2000年代前半のWebページを載せてみます。
今との比較で質素さに驚くサイトや、今はなき企業のサイトをピックアップしてみたので、懐かしさを覚える人もいるのではないかと思います。
2000年のYahoo! JAPAN
まずは2000年3月のYahoo! JAPANのTOPページです。

上部にいくつかの画像がある程度で、あとはテキスト中心のHTMLでデザインされた非常にシンプルな造りになっていますね。CSSもHTMLファイルに直接記述する構造で、今では俳優の阿部寛さんの公式ページでしかみないような、個人が手作りした感のあるWebページが多く存在した時代です。
この時代は、画像を載せると回線の細さでページの読み込みが遅くなるため、基本的にテキスト中心のコンテンツが主流でした。家庭ではモデムを介して電話回線を使ってインターネットに接続する時代で、2000年は東京都心でADSLが提供され始めた年でもあります。大学などに敷かれていたT3回線のような専用線と呼ばれるバックボーンの太い回線が重宝されていた時代ですね。
この時代から24年後のヤフージャパンのトップページです。非常に見覚えのあるページですね。
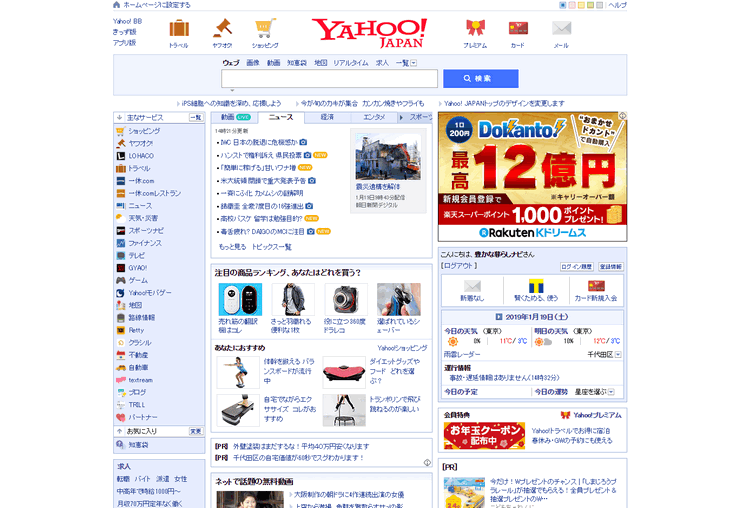
PC端末の高解像度化が進んだことで画面の幅も広くなり、何より画面が圧倒的にリッチになっているのが分かります。もはや単一のHTMLを見ても表示されるページを想像するのは困難で、見えないところも含めて、約24年分の技術革新が詰まったページと言えそうです。
2000年の楽天市場
今では携帯電話のキャリア事業まで始めた楽天グループですが、下記画面の2000年3月当時は楽天市場と楽天オークション(現在はサービス終了)しかサービスがなかった時代です。
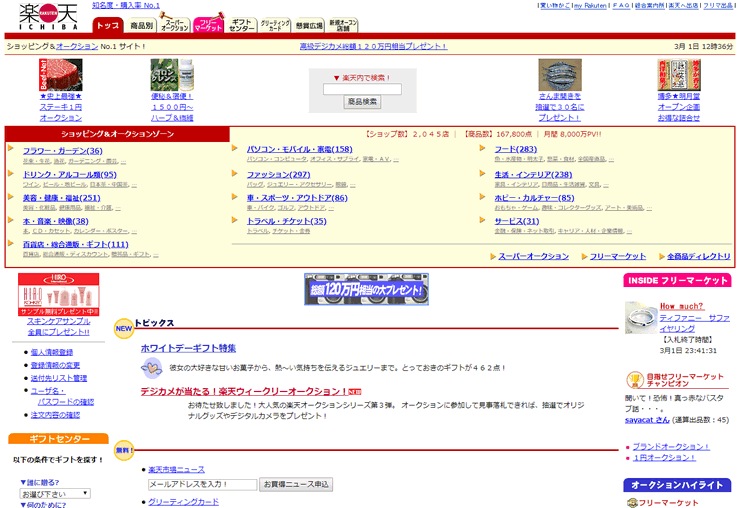
ECサイトということもあり、同じ時期のYahoo! JAPANとは違い軽い画像が多く使われていますね。さらに画面はwidthを100%にしていて、端末の解像度に関わらず、横一杯に画面を使っていることが分かります。
ちなみに、楽天はこの年の4月にジャスダック(現在の東証グロース市場)へ上場しています。ということで、これがJASDAQ上場企業のTOPページという話でもあります(ヤフーも同じです)。
2003年の武富士
選んだことに何の理由もありませんが、既に存在しない企業のWebサイトとして消費者金融(サラ金)の武富士のサイトをピックアップしてみました。下記は2003年の武富士のトップページです。

3年前の2000年のYahoo!・楽天市場と違って、少し画面がリッチになった感がありますね。ひとえにADSLの普及によるブロードバンド化が少し進んだ結果でしょう。バナー画像に関しては、現代のページで表示されていても違和感ないレベルにも見えます。
このように、現在は存在していない企業のWebページも見られるのがInternet Archiveの特徴の一つです。
2004年の松下電器産業(現・パナソニック)
若い人は知らないと思いますが、以下はPanasonicとNationalという2大ブランドで電化製品を販売していた松下電器産業(現・パナソニック)の企業情報ページです。
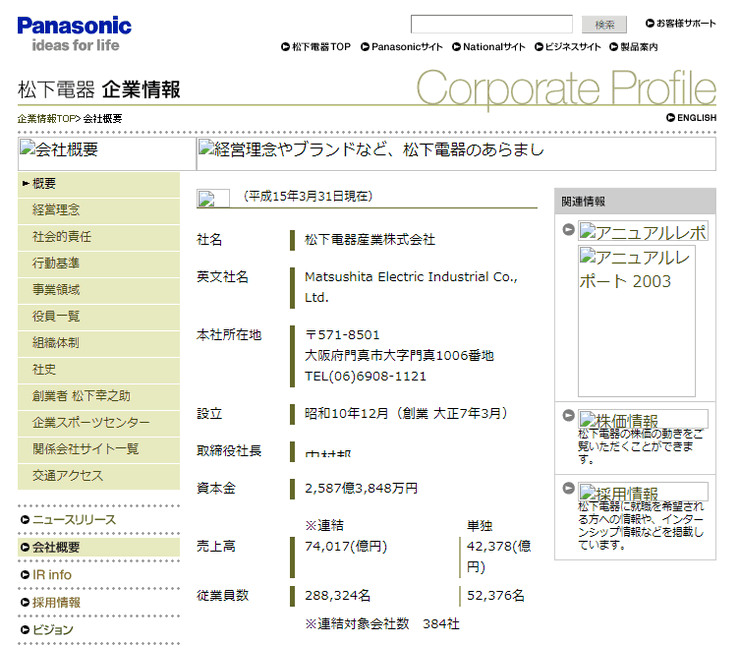
これは一部の画像がうまく保存されていないページの例です。アニュアルレポートなどの見出しと思われる部分がALT(画像の代替テキスト)の情報になっています。ちなみに、2008年10月1日に社名をパナソニックに変更したため、現在は1935年から続いた松下電器産業という企業名もWebサイトもありません。
2006年のイーバンク銀行(現・楽天銀行)
会社設立自体はジャパンネット銀行のほうが早いですが、今や楽天グループ入りしてネット専業銀行の圧倒的最大手となった旧・イーバンク銀行です。
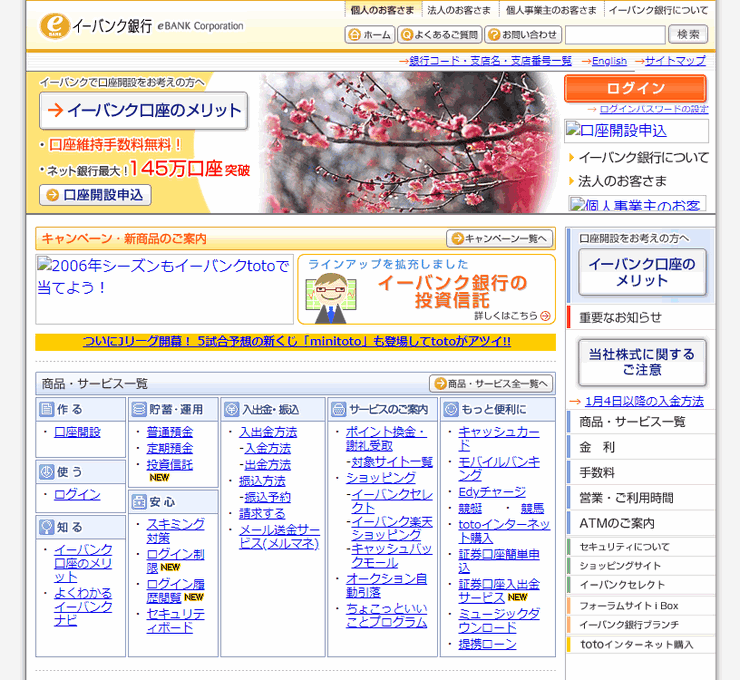
さすがに2006年までくるとブロードバンド全盛期になってきて、個々のリンクもテキストではなく画像を使うほどページがリッチになっています。見た目がこのレベルのサイトは、2024年現在にあっても違和感ないレベルではないでしょうか。もちろん、イーバンク銀行は既に存在せず、社名以外にドメインもebank.co.jpからrakuten-bank.co.jpに変更されています。
このような形で、今は存在しないドメインのページを見ることもできるので、興味があるかたは是非活用してみてください。
アーカイブすることを依頼する方法
Internet Archiveには、Wayback MachineのクロールやALEXA.comの情報送信を待つのではなく、自分からWebページのアーカイブを能動的に依頼する方法もあります。その方法は簡単で、Internet Archiveトップページにある "Save Page Now" にクロールして欲しいURLを入力するだけです。
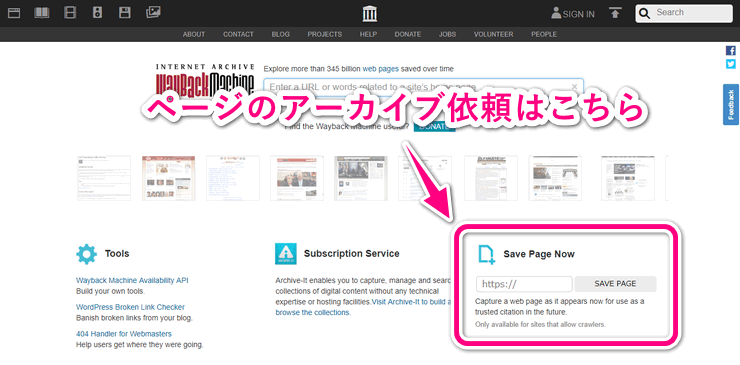
URLを入力して送信すると対象サイトのWebページが表示されて、Internet Archiveにアーカイブされたページが表示されます。少しだけ時間がかかりますが、ほぼリアルタイムです。
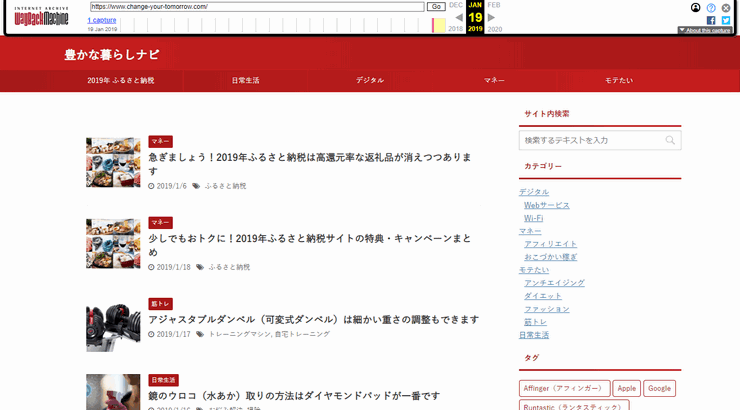
このサイトは全くアーカイブされていなかったので、今回初めてアーカイブされました。
クローラーがWebページを解釈する精度の問題もありますが、ウェブ魚拓のような使い方もできますね。ウェブ魚拓は見た目の完全性が担保される画面キャプチャですが、Wayback Machineはリンクや動きも保存する一方で完全性は担保されない点が異なります。
Internet Archiveは幅広い用途に使えます
最後に、私が考えるInternet Archiveの用途について書いておきたいと思います。
冒頭にも書いたとおり、私は顧客との裁判外紛争の資料としてInternet Archiveを使いました。10年以上前のWebページの表示内容を求められ、それを客観的に説明する資料として、原因となった時期のページのアーカイブを資料として提出しています。結果、特に証拠としては問題ありませんでした。
他にも、中古ドメインを購入した際、そのドメインが過去に何をやっていたサイトだったのかを調べる目的でも活用しました。今後も機会があれば必ず使うでしょう。他にも、過去のキャンペーンやお知らせを保存しない(削除してしまう)企業サイトも多くあるので、消えてしまったページを再確認する目的でも使えそうですね。
このような活用方法は他にも色々と考えられると思うので、今はお遊びレベルでしか考えられなくても、ぜひ頭の片隅にWayback Machineというサービスがあることを置いておいてください。きっと役立つ日が来ると思います。
最後まで読んでいただき、ありがとうございました。この記事が、今はなきWebページを確認・活用する方法を知るお役に立てば幸いです。




